All That Whispers
I wanted to summarize the various projects and links related to OpenAI’s Whisper transcription software and model. Here is what I have discovered and noticed, collected into one place.
This article is now too old to be useful. I’ll write a new post but the TLDR is: just use whisper.cpp. It has excelent CUDA support if you have an Nvidia GPU, even the standard build uses the GPU/Metal on Macs, and the CoreML version is even better on Apple Silicon Macs.
If you have an Nvidia GPU (and patience), you could try Insanely Fast Whisper
Other Implementations
Whisper.cpp
For Mac users, or anyone who doesn’t have access to a CUDA GPU for Pytorch, whisper.cpp almost certainly offers better performance than the python/pytorch implementation. In testing it’s about 50% faster than using pytorch and cpu.
Whisper CPP supports CoreML on MacOS!
Major breakthrough, Whisper.cpp supports CoreML on MacOS! There are some caveats. Converting to CoreML format is slow, for the small.en model, this took 20 minutes maybe? And the first time it runs on a device it is slow. Probably another 15 minutes for the initial run on my M1 Mac Mini (16 GB of RAM). But then I was able to transcribe a 2 1/2 hour podcast with the small.en model in 10 minutes.
It’s also not exactly intuitive. One has to create the CoreML model, compile whisper.cpp, be patient both at conversion and on first run, and convert the audio file to the right .wav format first. But, now that it’s set up, I think for me it’l be easier to transcribe on my Mac rather than boot up my Windows PC and its aging python environment to run on my Nvidia GPU. I’ll probably write some sort of helper script that handles some of these intermediate steps like the conversion to wav with ffpmeg.
Metal Backend. You might have heard that PyTorch supports the Apple Silicon GPU via the ‘metal shaders’ for Pytorch. And one might think that could speed up Whisper in Python on a Mac. Alas, the MPS backend is missing at least one needed operator (
aten::repeat_interleave.self_int). So, in my testing it falls back to CPU, takes 20 times longer than the CPU backend by itself, and then … doesn’t actually work. (It returned gibberish.) You can track the various yet-unimplemented pytorch operations here.
MacWhisper
Based on whisper.cpp, we have MacWhisper which is a GUI application that will transcribe audio files. It doesn’t yet have a lot of export options (I’m hoping for .vtt export), but it is convenient all-in-one way to try out Whisper on a Mac.
Whisper in Huggingface Transformers- with Tensorflow support (on MacOS, the GPU sort of works!)
I was excited to see thisWhisper in Transformers news because perhaps coupled with metal support in Tensorflow, I could finally use a GPU to do whisper transcription. I followed these instructions from Apple and then tried to do this colab notebook locally and it crashed with:
RuntimeError: Failed to import transformers.models.whisper.modeling_tf_whisper because of the following error (look up to see its traceback):
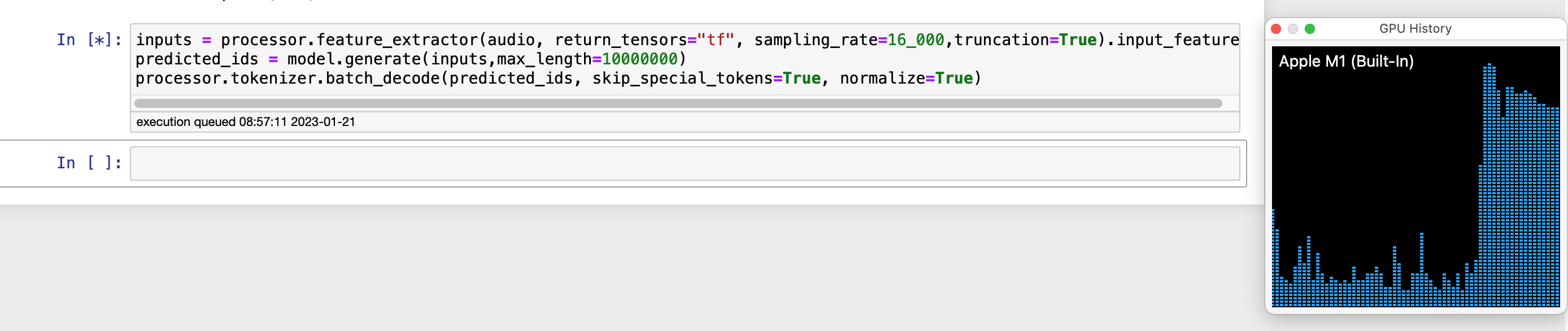
No module named 'keras.saving.hdf5_format'UPDATE: The GPU! It does something! Ok, so I installed transformers from their github (pip install git+https://github.com/huggingface/transformers.git), the error above went a way, did everything in a fresh new conda environment, and I got this implementation of whisper to run on the M1 GPU via Tensorflow!
Speeds seem ironically comparable to whisper.cpp. 1m43s. vs 1m52s, and I had to cut out the first few seconds for the TF implementation as the music at the front of the episode confused the transcription. I have 8 GPU cores and 8 CPU cores so perhaps not that surprising? I’m a little surprised. My test was an episode of Robot or Not. I had to convert it to 32bit float wav file, and then pull that into a numpy array. Code below:
### ran this first ffmpeg -i robot250-newyear.mp3 -acodec pcm_f32le -ac 1 -ar 16000 output.wav
import scipy
_, audio = scipy.io.wavfile.read('output.wav')
import numpy as np
from transformers import TFWhisperForConditionalGeneration, WhisperProcessor
model = TFWhisperForConditionalGeneration.from_pretrained("openai/whisper-medium")
processor = WhisperProcessor.from_pretrained("openai/whisper-medium")
audio = audio[64000:]
audio = list(np.array_split(audio,8,))
inputs = processor.feature_extractor(audio,
return_tensors="tf",
sampling_rate=16_000,
truncation=True).input_features
predicted_ids = model.generate(inputs, max_length=10000000)
processor.tokenizer.batch_decode(predicted_ids,
skip_special_tokens=True,
normalize=True)
I had to manually make a list of smaller arrays as it wouldn’t just work on one big numpy array. But look at the GPU go. A reliable and easy to install implementation that runs on the GPU will one day be pretty fast, especially on Apple Silicon macs with large GPU core counts.
CoreML
Two things I stumbled upon googling: this repository on an CoreML version of Whisper (not updated since the initial commit in September 2022), and this somewhat-cryptic blog post about a similar CoreML effort/app, yet unpublished effort.
This fork of the first repo seems the farthest (furthest?) along, but when I cloned the repo and tried to build it in Xcode, I did not have much success. (Specifically, it was looking for decoder and decoder_base.mlpackage files and even when I provided both, the compiler had other complaints.)
WhisperX
I just heard of WhisperX, with better timestamp accuracy and a beta of speaker identification.